Khi bạn trả phí thuê bao hàng tháng, bạn kỳ vọng dịch vụ sẽ hoạt động hoàn hảo. Và khi làm việc với các công cụ AI, việc bị giới hạn tốc độ truy cập giữa chừng có thể là một trải nghiệm khá khó chịu. Chưa kể đến việc tất cả công việc của bạn, và bất kỳ tệp hoặc tài liệu nhạy cảm nào bạn đang làm việc, đều đang được gửi đến một máy chủ không xác định.
- Viết kịch bản shell mà không cần tra cứu từng lệnh trên Google.
- Tóm tắt các tập tin nhạy cảm mà không cần gửi chúng đi bất cứ đâu.
- Hỗ trợ lập trình ngoại tuyến hiểu rõ cấu hình hệ thống của bạn.
- Biến những cuộc họp lộn xộn thành những ghi chú gọn gàng, hữu ích.
- Một trợ lý cá nhân không bao giờ cần kết nối internet.
May mắn thay, có rất nhiều ứng dụng bạn có thể sử dụng để tận hưởng các mô hình trí tuệ nhân tạo (LLM) cục bộ . Các LLM cục bộ cũng đã tiến bộ rất nhiều, đến mức bạn có thể chạy các mô hình AI nhẹ trên hầu hết mọi thiết bị. Chúng không giỏi mọi thứ, nhưng chúng thực hiện một số tác vụ tốt đến mức bạn sẽ muốn hủy ngay lập tức gói đăng ký AI đám mây của mình.
Viết kịch bản shell mà không cần tra cứu từng lệnh trên Google.
Thử một câu tiếng Anh đơn giản để các tập lệnh bash hoạt động





Đây là lý do tôi thường xuyên sử dụng các mô hình LLM cục bộ của mình. Mô tả một tác vụ hệ thống đơn giản và lặp đi lặp lại bằng ngôn ngữ dễ hiểu và nhận được một kịch bản Bash hoặc Python hoạt động chỉ trong vài giây sẽ tiết kiệm được nhiều thời gian hơn bạn tưởng. Nó hoàn hảo để tạo ra các kịch bản nhanh chóng để đổi tên nhiều tệp, nén và di chuyển thư mục hoặc tự động hóa việc bảo trì hệ thống cơ bản. Các mô hình AI cũng có thể giải thích chức năng của từng cờ và đối số, có nghĩa là chúng cũng rất tuyệt vời cho bất kỳ công cụ dòng lệnh nào mà bạn quen thuộc nhưng không nhất thiết phải biết cách sử dụng.
Ngoài ra, khi các tập lệnh này tác động đến hệ thống tệp, cấu trúc thư mục, tác vụ định kỳ (cron jobs) hoặc đường dẫn máy chủ nội bộ của bạn, không có bất kỳ thông tin nào trong số đó rời khỏi máy tính của bạn, điều này rất quan trọng nếu bạn quan tâm đến việc các công cụ của bạn có thể truy cập được bao nhiêu thông tin về thiết lập của bạn. Việc mô tả các lệnh hoặc tác vụ này cho AI đám mây có thể làm lộ đường dẫn tệp, quy ước đặt tên và thậm chí cả gợi ý về cấu trúc máy chủ của bạn. Một mô hình cục bộ cũng thấy thông tin tương tự, và thông tin đó không bao giờ rời khỏi hệ thống của bạn.
Tóm tắt các tập tin nhạy cảm mà không cần gửi chúng đi bất cứ đâu.
Giữ bí mật tuyệt đối các tài liệu riêng tư
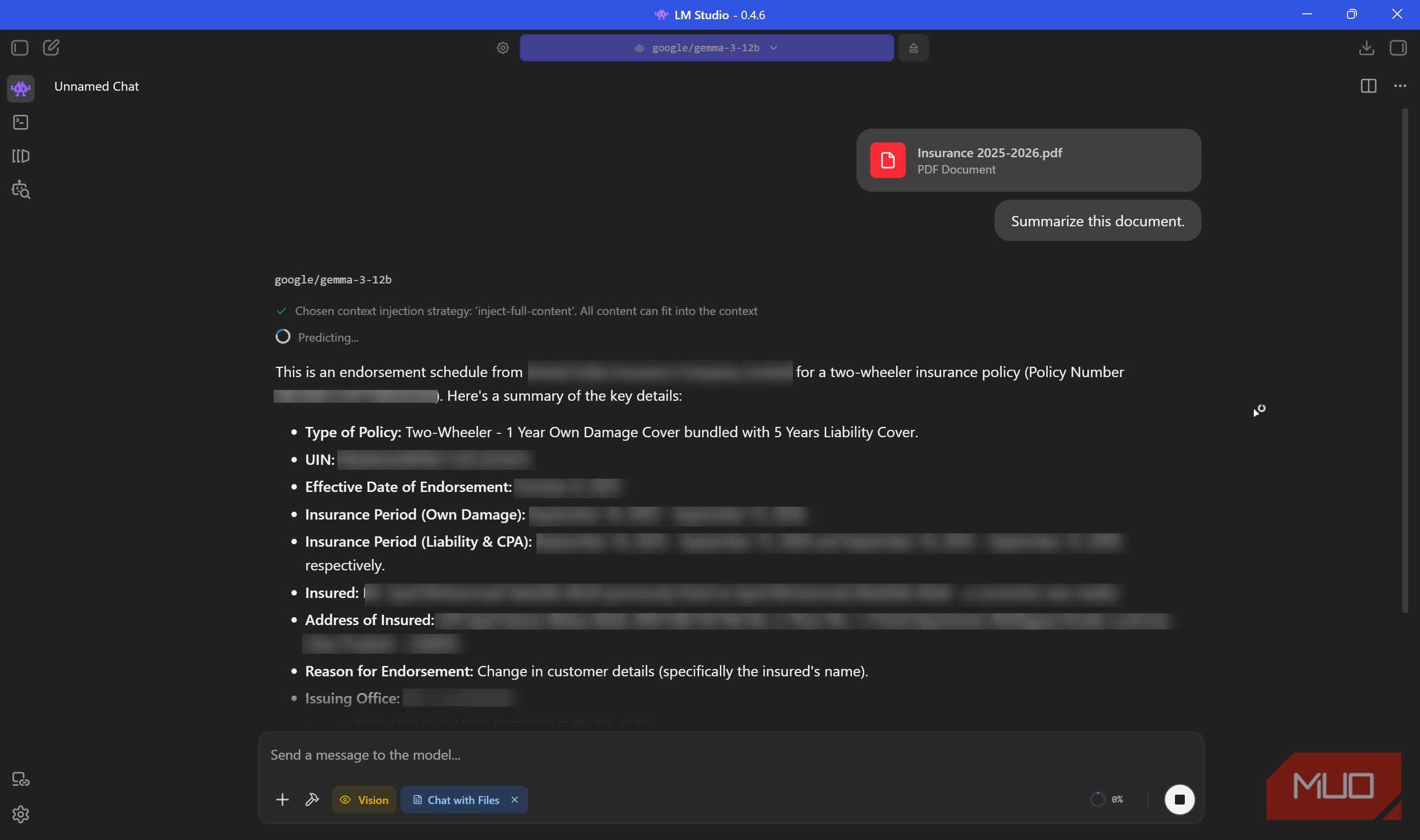
Một ứng dụng khá thuyết phục khác của LLM cục bộ là tóm tắt các tài liệu riêng tư. Bạn không cần phải nhập hợp đồng, báo cáo mật từ công ty, hồ sơ y tế hoặc báo cáo tài chính cá nhân vào máy chủ trực tuyến. Các hệ thống AI đám mây, bất kể chính sách bảo mật của chúng, đều liên quan đến việc dữ liệu của bạn rời khỏi thiết bị và được xử lý trên cơ sở hạ tầng bên ngoài. AI cục bộ loại bỏ hoàn toàn rủi ro đó.
Các công cụ như Ollama kết hợp với LangChain có thể tạo ra toàn bộ quy trình tóm tắt tài liệu riêng tư chạy hoàn toàn trên phần cứng của bạn. Bạn chỉ cần trỏ mô hình đến một tệp PDF, nó sẽ đọc và tóm tắt nội dung đó, và ở bất kỳ thời điểm nào, nội dung đó cũng không được chuyển đến máy chủ của bên thứ ba. Đối với bất kỳ ai quan tâm đến tính bảo mật của dữ liệu, đây là một lợi thế không thể thiếu.
Hỗ trợ lập trình ngoại tuyến hiểu rõ cấu hình hệ thống của bạn.
Gỡ lỗi mà không cần internet (và không giới hạn)
Lập trình bằng các công cụ AI luôn tiềm ẩn rủi ro, đặc biệt nếu bạn đang làm việc với các API nội bộ, xử lý dữ liệu khách hàng hoặc logic độc quyền. Bạn chắc chắn không muốn gửi mã nguồn gốc, nhạy cảm đến máy chủ hoặc thậm chí cơ sở hạ tầng của bên thứ ba. Điều này có thể chấp nhận được đối với những người đam mê hoặc các dự án cá nhân, nhưng nó trở nên thiếu thận trọng đối với bất kỳ dự án nào mang tính thương mại nhạy cảm.
Giải pháp đơn giản là tự tạo một trợ lý lập trình AI cục bộ. Tôi đã tự xây dựng một trợ lý lập trình AI cục bộ cho VS Code và nó hoạt động tốt đến bất ngờ. Có thể nó không nhanh bằng các dịch vụ AI dựa trên đám mây, nhưng tùy thuộc vào phần cứng và kiểu máy bạn đang sử dụng, các trợ lý lập trình AI cục bộ có thể đạt hiệu suất khá gần. Vì không có lưu lượng mạng truyền qua lại giữa các máy chủ, nên việc tự động hoàn thành từng dòng cũng nhanh hơn nhiều. Đối với phần lớn các tác vụ lập trình hàng ngày—viết các hàm tiện ích, gỡ lỗi cây ngăn xếp, tạo mã mẫu hoặc giải thích cú pháp thư viện không quen thuộc, một trợ lý lập trình AI cục bộ có thể hoạt động rất tốt.
Biến những cuộc họp lộn xộn thành những ghi chú gọn gàng, hữu ích.
Không cần tải lên, không bị chậm trễ, không có vấn đề riêng tư khó xử.
Cũng giống như việc bạn không muốn mã nguồn độc quyền được xử lý thông qua cơ sở hạ tầng máy chủ của bên thứ ba, bạn cũng không muốn các cuộc họp và cuộc trò chuyện công việc của mình được lưu trữ ở đó. May mắn thay, bạn có thể dễ dàng xây dựng một hệ thống phiên âm và tóm tắt bằng AI cục bộ dựa trên các công cụ như Whisper để chuyển đổi giọng nói thành văn bản và một hệ thống LLM cục bộ để tạo bản tóm tắt.
Cần lưu ý rằng quá trình thiết lập ban đầu có hơi phức tạp, nhưng phần mềm hoạt động hiệu quả trên hầu hết các thiết bị phần cứng thông thường. Kết quả là một quy trình làm việc mà bạn hoàn toàn kiểm soát được mọi thứ. Chất lượng tóm tắt sử dụng phương pháp phân đoạn giảm thiểu bằng bản đồ (map-reduced chunking), về cơ bản là chia nhỏ các bản ghi dài thành các phần nhỏ hơn, tóm tắt từng phần rồi kết hợp lại, chỉ mất chưa đến 10 giây đối với hầu hết các tài liệu và bản ghi, và đủ tốt cho việc sử dụng nội bộ. Nó cũng giúp giảm đáng kể thời gian ghi chú.
Một trợ lý cá nhân không bao giờ cần kết nối internet.
Trả lời nhanh chóng mà không giới hạn số lần truy cập hoặc yêu cầu đăng nhập.
Hàng ngày, chúng ta sử dụng AI đám mây cho rất nhiều câu hỏi không quan trọng hoặc các tác vụ thường ngày mà bạn không muốn tốn nhiều công sức suy nghĩ. Việc yêu cầu AI giải thích thông báo lỗi, giải mã lệnh Linux và viết lại email đều là những tác vụ mà các mô hình cục bộ có thể xử lý tốt, và không có lý do gì để phải chuyển chúng lên máy chủ đám mây khi một mô hình cục bộ có thể trả lời chính xác chỉ trong vài giây. Khi một mô hình cục bộ đang chạy, chi phí cho mỗi truy vấn gần như bằng không — không có phí đăng ký và không có giới hạn số lượng truy vấn.
Việc chạy các mô hình như Mistral 7B hoặc Gemma thông qua LM Studio hoặc Ollama cung cấp cho bạn một trợ lý AI nhanh chóng và ổn định, hoạt động ngoại tuyến, khởi động nhanh và không quan tâm bạn đặt bao nhiêu câu hỏi mỗi ngày. Đối với việc sử dụng thường ngày trong công việc, chiếm phần lớn tương tác của chúng ta với các công cụ AI trực tuyến, điều này là quá đủ.
Trí tuệ nhân tạo cục bộ không hoàn hảo, nhưng nó có khả năng hơn bạn tưởng.
Điều này không có nghĩa là các mô hình LLM cục bộ luôn tốt hơn. Đối với các tác vụ suy luận phức tạp hơn, tạo mã tiên tiến, làm việc với các ngữ cảnh rất lớn hoặc truy cập internet, các mô hình đám mây vẫn có ưu thế thực sự. Yêu cầu phần cứng cũng là một yếu tố cần xem xét. Bạn có thể không cần một GPU mạnh mẽ để chạy các mô hình AI , nhưng nếu bạn đang thực hiện công việc đòi hỏi cao, bạn sẽ cần phần cứng đủ mạnh để hỗ trợ một mô hình AI đủ mạnh.
Tuy nhiên, giá trị mà chúng mang lại đã thay đổi. Khi các mô hình mã nguồn mở như Llama, Mistral và DeekSeek trưởng thành, khoảng cách về chất lượng với AI đám mây ngày càng thu hẹp, ít nhất là đối với các tác vụ cơ bản hàng ngày. Những gì bạn nhận được đổi lại—kiểm soát hoàn toàn dữ liệu của mình, không phát sinh chi phí định kỳ, khả năng hoạt động ngoại tuyến và không giới hạn số lần sử dụng—là một sự đánh đổi xứng đáng với công sức bỏ ra.